Generalization
Generalization의 필요성
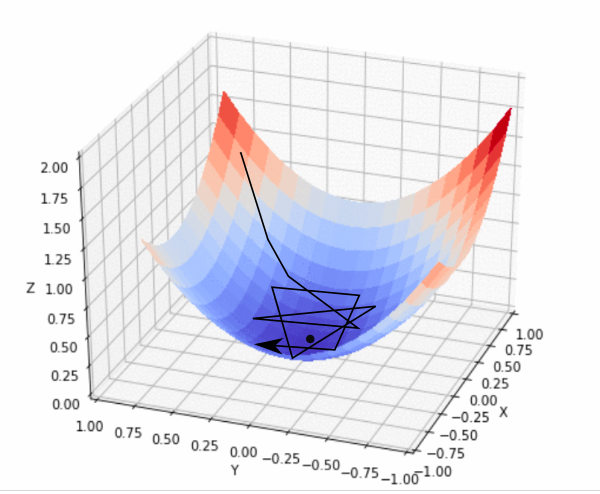
머신러닝에서 학습은 Train Loss를 줄이는 방향으로 진행된다. 하지만 우리가 원하는 것은 Training data에 대한 손실을 최소화하는 것이 아니라, 앞으로 우리의 모델이 마주하게 될 본적 없는 새로운 데이터를 잘 분류하는 것이고, 이를 위해 우리는 우리의 모델을 일반화(Generalization)해야 한다.
즉, 모델이 Training data에 너무 맞춰지면 본적 없는 데이터에 제대로 대처하지 못한다.
방법
1. 차원을 줄인다.
필요없는 input feature를 줄임으로써 우리의 모델이 너무 커지는 것(Training data에 민감해지는 것)을 방지한다.
2. Regularize
$w$의 크기가 너무 커지지 않도록 한다. 전 강의에서 학습한 Gradient Descent를 예로 들면, 일반적으로 $\lvert \vec{w} \rvert$ 는 학습이 진행됨에 따라 커지는데, TrainLoss 이외에도 $\lvert \vec{w} \rvert$ 에 대한 제약을 줌으로써 $w$의 크기를 조절한다. ($min_\vec{w} (TrainLoss(\vec{w}) + \frac{\lambda}{2} \lvert \vec{w} \rvert^2)$)
Gradient Descent는 다음과 같이 진행한다.
$\vec{w} = \vec{w} - \eta(\triangledown_\vec{w} Loss(\vec{w,y,w}) + \lambda \lvert \vec{w} \rvert) $
이러한 방식을 L2 Regularization이라 한다.
3. Training data로 부터 일부를 떼어 Validation data로 활용한다.
Test data를 활용하지 않으면서, 새로운 데이터에 대한 반응을 보기 위하여 Training data 중 일부를 떼어 Validation data로 활용한다.
K mean clustering
Unsupervised learning
보통 라벨링된 데이터는 구하기 매우 힘들다. 또한 데이터들은 그 자체로 여러가지 특징들을 가지고 있는데, 이러한 특징들을 자동적으로 찾아 분류하는 방법이다.
K mean clustering
데이터들을 K개의 cluster로 묶는 방법이며, 각 데이터 $\phi(x)$를 cluster $k$의 centroid인 $\mu_k$ 중 centroid가 가장 가까운 cluster에 배정하는 방식이다. 이때 손실이 최소화되는 centroid의 위치를 찾는 방식으로 진행된다. 손실함수는 다음과 같이 모든 data로부터 소속된 cluster의 centroid까지의 거리의 합으로 정의한다.
$Loss_{kmeans}(z,\mu) = \sum_i \lvert \phi(x) - \mu_{z_i} \rvert ^2$
Python Code
먼저 클러스터링에 필요한 함수들을 정의합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
#유클리드 거리 계산
def get_distance(p1, p2):
return np.sqrt((p1[0]-p2[0])**2+(p1[1]-p2[1])**2)
#주어진 centroid로 sample들에 클러스터 할당
def clustering(centroid,sample):
label = []
for s in sample:
dist = [get_distance(s,c) for c in centroid]
label.append(dist.index(min(dist)))
return label
#에러 계산(유클리드 거리의 합)
def get_error(centroid,sample,label):
err = 0
for i, v in enumerate(sample):
err += get_distance(v,centroid[label[i]])
return err
#sample들이 각 클러스터에 할당되었을 때, 새로운 centroid 계산
def get_centroid(sample,label):
s1=[]
s2=[]
for i in range(len(label)):
if label[i] == 0:
s1.append(sample[i])
else :
s2.append(sample[i])
s1=np.array(s1)
s2=np.array(s2)
return np.array([(np.mean(s1[:,0]),np.mean(s1[:,1])),(np.mean(s2[:,0]),np.mean(s2[:,1]))])
|
cs |

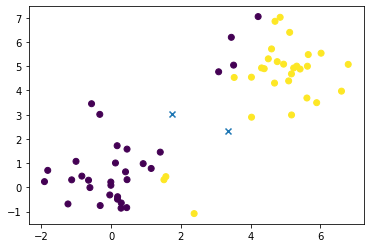

클러스터의 개수는 2개로 고정하기로하고, 클러스터들의 첫 centroid는 램덤으로 주게되는데, 여기서는 편의상 (6,0)과 (0,6)으로 하겠습니다. 그러면 각 sample들은 색깔로 표시한 것과 같이 클러스터링 되게 됩니다. 여기까지가 아래 코드의 line4까지가 됩니다. 첫 그림에서는 $y=x$ 그래프를 기준으로 위 아래로 나누어진것을 확인할 수 있습니다.
line6부터는 새로 할당된 클러스터들에 대하여 centroid를 다시 계산하고 이전의 에러보다 현재의 에러가 작은 경우, 바뀐 centroid를 채택하고 cluster를 다시 배정하게 됩니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 초기
centroid = np.array([(0,6) , (6,0)])
label = clustering(centroid,sample)
err = get_error(centroid,sample,label)
for i in range(5):
new_centroid = get_centroid(sample,label)
label = clustering(new_centroid,sample)
new_err = get_error(new_centroid,sample,label)
if new_err < err:
err = new_err
centroid = new_centroid
else :
break
|
cs |
* K-means 알고리즘에서 중요한 것은, K-means 알고리즘은 항상 local minimum에 도달하긴 하지만, 그곳이 global minimum이라는 보장은 없으며, 초기조건을 바꾸어가며 가장 적절한 centroid들을 찾아야 합니다.
Reference
'ML > CS221 Stanford' 카테고리의 다른 글
| On-Policy 와 Off-Policy (0) | 2020.03.21 |
|---|---|
| Lecture 9. Game playing 1 (0) | 2020.03.11 |
| Lecture 8: Markov Decision Processes - Reinforcement Learning (0) | 2020.02.27 |
| Lecture 7: Markov Decision Processes - Value Iteration (0) | 2020.02.25 |
| Lecture2 Linear classifiers, SGD (0) | 2020.02.18 |